Introducción a ElasticSearch
Introducción a ElasticSearch
Estes días no traballo, un compañeiro, fíxonos unha breve introdcucción a ElasticSearch. Polo que para tratar de asentar un pouco máis algúns conceptos, aproveito a deixalo aquí por escrito. Aínda que de xeito resumido, falarei da topoloxía e algo do manexo desta aplicación.
ElasticSearch é unha aplicación que permite almacenar a información como JSON. Deste xeito permite facer buscas en tempo real nos datos. Ten librarías para varias linguaxes, como poden ser Java, C#, PHP, Python, Ruby, etc. Isto permite que moitas veces se utilice a modo de caché, ou almacén de proxeccións. En lugar de facer complexas consultas contra as bases de datos, almacenanse os resultados en ElasticSearch. Deste xeito cando queremos recuperar os datos, aforramos ter que facer Joins, ou outras operacións, reducindo moito o tempo de consulta dos clientes.
Hai outro proxecto, Kibana, que permite facer consultas nunha interface web. Deste xeito podemos navegar polos datos e polos índices xerados na aplicación. Estes índices veñen a ser coma un histórico de xeracións almacenadas. Por exemplo, se o último índice tivese algún erro, rapidamente poderíamos apuntar ao índice anterior.
Unha vez presentado imos ver algúns datos sobre ElasticSearch.
Topoloxía de ElasticSearch
A forma máis básica de topoloxía para ElasticSearch ben a ser un único nodo co seu almacén de datos. Cando un cliente fixese unha consulta a, accedería a este nodo e este devolvería a información do seu almacén. Sería algo como a figura seguinte.

Como podemos ver na imaxe, o noso nodo de ElasticSearch é o nodo mestre.
Sen importar que só teñamos un nodo, ou varios, sempre temos que ter un
nodo mestre.
No caso de que a nosa aplicación escalase e tivésemos que aumentar os nodos,
para dar servizo a un maior número de clientes, aparecería a figura do
coordinador. O cliente que quixese facer unha consulta, conectaría co
coordinador e este consultaría ao nodo adecuado. Unha representación básica
pode ser vista na seguinte imaxe.

Como podemos ver na última imaxe, para varios nodos precisamos do coordinador. E cada nodo sempre terá o seu propio almacén, sen importar se son mestre ou non.
Tipos de nodos: Roles
Hai distintos tipos de nodos, a continuación veremos algúns deles.
Nodos mestres
Tan só teremos un por cluster, que se encargará da creación e borrado dos índices. Tamén é responsable de acomodar os fragmentos de información de cada nodo. É elexido por un sistema de poxas automático.
Nodos de datos (quente, temperado, frío e xeado)
Estes nodos conteñen os datos e índices para buscar, así como ínidices para Agregar, ordear ou outras funcións.
Outros nodos
- Nodos de Machine Learning (ML)
- Nodos de Inxesta (Ingest)
- Nodos de Coordinación
Distribución dos datos en nodos
Índices
Cando a información se distribúe, tanto se é nun só nodo, como en varios; teremos indices para localizalos. Estes índices funcionan como espazos (Namespaces) que nos dín onde está almacenada a información. Dicir tamén que estes índices poden estar distribuídos nun ou varios fragmentos.
Fragmentos (Shards)
Un fragmento ven a ser como o índice dunha instancia. Ten o seu propio índice Lucene, que é o motor de busca. Busca que fai sobre un subconxunto de datos. As recomendacións cando traballamos con Shards son menos de vinte fragmentos por nodo, por xiga. Hai que ter conta tamén de como os configuramos. Usar fragmentos pequenos incrementa a sobrecarga de segmentación, mentres que usalos demasiado grandes incrementa a problemática da recuperación, do nodo despois dun erro.
Réplicas
Unha réplica é unha copia, que permitiría en caso de erro dun nodo, apuntar directamente á réplica. Recuperando o funcionamento máis rápido.
Distribución dos datos por topoloxías
Aquí podemos ver algúns exemplos de como ElasticSearch distribúe os datos. Neste caso según a topoloxía que nos lle configuremos:








Estados dos índices
Os índices que xeremos en ElasticSearch, poden ter tres estados, que para facelos máis visuais van asignados a cores:
- Verde: todo-los fragmentos ou shards están asignados.
- Amarelo: todo-los fragmentos primarios están asignados, pero un ou máis fragmentos replicados están sen asignar.
- Vermello: un ou máis fragmentos primarios están sen asignar, polo que hai datos non dispoñibles.
Nos dous primeiros estados, o sistema é funcional e todo-los datos accesibles. No estado vermello, non poderemos traballar.
Operacións sobre ElasticSearch
Lectura
Un exemplo dunha operación de lectura sería o seguinte:
- Recibimos unha petición, por exemplo con cURL.
- Esta chega ao Nodo coordinador.
- Que enruta cara o grupo de shards que conteñen a información.
- Ca selección de réplicas adaptable (ARS) accede aos datos.
- O nodo coordinador agrupa toda-las respostas das réplicas.
- Devolvemos a información ao cliente.
O uso da ARS fai que ElasticSearch busque a información nas réplicas dos nodos sen sobrecarga, deixando as consultas nestes nodos, cando non quede máis remedio. No caso de non utilizar a ARS, buscaría en todo-los nodos, incluídos aqueles con un alto estrés de traballo.
Escritura
Os índices en ElasticSearch están divididos en fragmentos (shards).
Estes fragmentos poden ter varias copias, que deben ser mantidas en
sincronía cando se engaden ou eliminan documentos.
Se isto non fose así, teríamos diferentes resultados creando
inconsistencias. O proceso que mantén a sincronía e serve os
datos nas lecturas é o modelo de replicación de datos.
Este modelo baséase en ter unha copia que actuará como fragmento primario.
Este primario será o punto de entrada para as operacións de indexación.
Tamén é o responsable de validalas e asegurar que son correctas.
Polo tanto, non será ata que o primario valide unha operación,
que a replicará ao resto de copias.
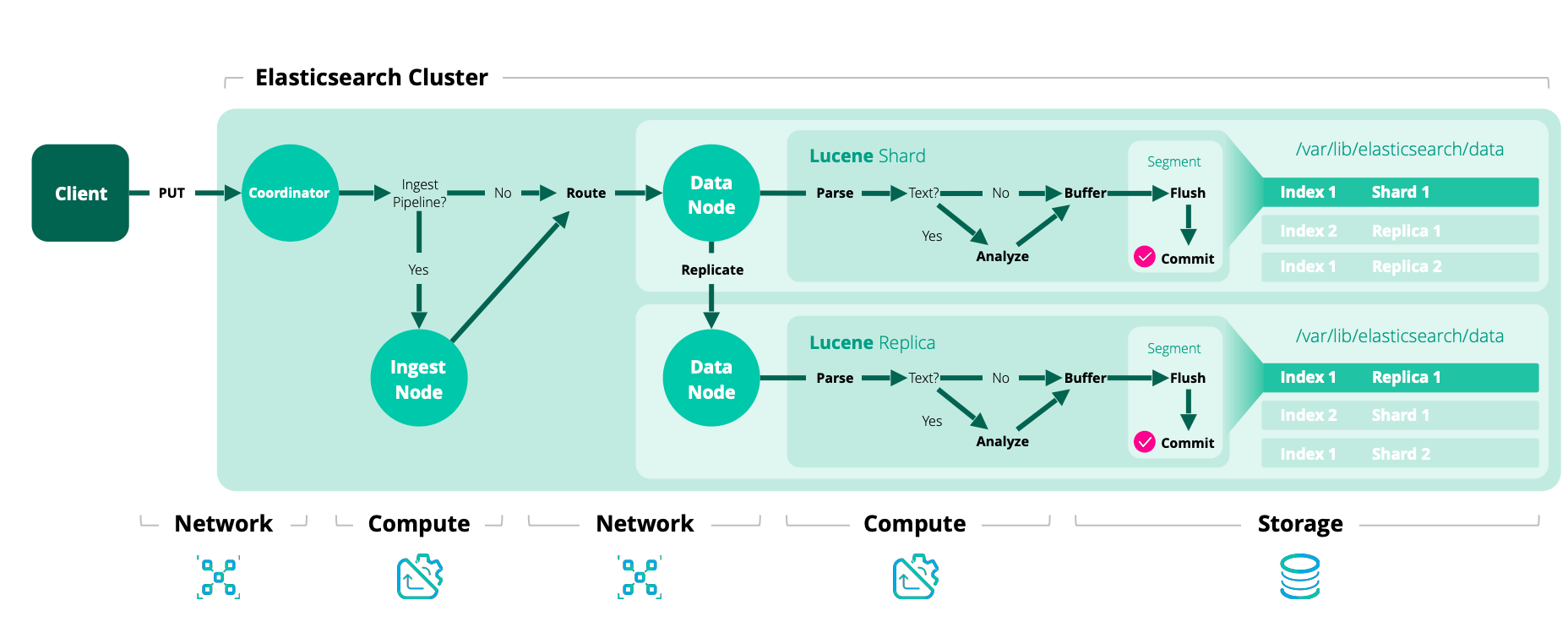
Etapa de coordinación: Cada operación enrútase cara un grupo réplica, xeralmente usando o ID do documento. Internamente chega ao primary shard.
Etapa primaria: O shard primario é o responsable de validar a operación e dirixila ás réplicas. O fluxo sería o seguinte:
- Valídase a operación solicitada e rexéitase se non é valida. Por exemplo cun campo que contén un tipo incorrecto.
- Executa a operación localmente, co que tamén valida o contido. Por exemplo se un campo é demasiado longo, rexeitarao.
- Sincroniza as réplicas.
- Unha vez as réplicas confirman a sincronización, devólvese o éxito á petición do cliente.
Etapa réplica: Cada réplica efectúa as operacións de indexado localmente.
Se durante este proceso ocorrese algún erro, o primario ten que respostar. Se o primario é o que está nun estado inviable para respostar, a operación agardará un minuto, despois promocionará outro nodo como primario.
Concurrencia de lectura/escritura
Cómo as lecturas e escrituras, deste sistema, poden ocorrer simultaneamente; o sistema ten que ser quen de manexar este escenario. O cal implica:
- Lecturas eficientes: En condicións normal só unha vez por cada grupo réplica relevante. Só en caso de erros, varias réplicas dun mesmo fragmento executarían a mesma consulta.
- Lectura sen confirmar: como o primario indexa e despois réplica a petición, é posible que unha lectura vexa o cambio antes de ser confirmado.
- Dúas copias por defecto: No caso de ter só duas copias, o sistema será tolerante a erros con elas. No caso de sistemas con máis copias precisará un mínimo de tres.
Erros
- Un shard vólvese lento ao indexar: pode ocorrer porque o primario agarda por toda-las réplicas. Un único shard lento afecta á eficiencia.
- Lecturas sucias: un nodo primario pode ter escrituras sen notificar. Isto pode darse nun entorno no que o primario esté illado, cando envía as peticións ás réplicas ou tenta contactar co nodo principal. A operación por tanto está indexada e pode ser lida concurrentemente. Para mitigar isto, cada segundo compróbase a conexión co master. Se se perde, as operacións de indexado serán rexeitadas.
Cómo funciona o análise de textos de ElasticSearch?
Como podemos ver na imaxe anterior, cando recibimos un texto este é analizado. Isto aplica unha serie de operacións, que serán:
- Filtro de carácteres: poder ter ningún ou varios. Filtran cousas como etiquetas html, ou cadeas que non queiramos procesar.
- O tokenizador estándar: só pode haber un. Aplica transformacións ás cadeas para buscas por proximidade. Por exemplo dar como coíncidencia perro con perros.
- Filtros de tokens: aplica unha serie de filtros ás cadeas, como pasalas a minúsculas, eliminar as que teñan menos carácteres dos requeridos, etc.
Tipos de datos
Cómo xa falamos de que no caso dos textos aplícase un análise, veremos agora que tipos de datos temos dispoñibles, e cómo buscar por eles.
- Boolean: a busca é por valor exácto, sen análise. Automáticamente convirte os valores. Por exemplo “False”, como cadea, é convertido a false.
- Float/integer: busca por valores exactos, sen análise e tamén forza a conversión de tipos. Por exemplo “4.3” será 4,3.
- Keyword: busca a coincidencia exacta, sen análise de termos. Permite funcións de Elastic, como agregar ou ordear.
- Texto: Busca polos valores analizados. Non se pode usar cas funcións de Elastic, como ordear ou agrupar.
- Obxecto: se está ben configurado, podemos buscar polos campos do obxecto. Este será transformado nun JSON plano. Admite análise dependendo da configuración dos campos. Así mesmo as funcións de Elastic, tamén dependerán desta configuración.
- Anidado: permite a busca por campos, se están ben marcados. Como contrapartida crea sub-documentos, o que incrementa a complexidade das buscas e o tempo. As análises dependen da configuración dos campos. Ao igual ca o anterior tipo, tamén admite funcións de Elastic, agregación e ordeado, segundo a configuración.
- Keyword como anidado: pódese conseguir que un keyword funcione coma un anidado, pero isto engade moita complexidade e cantos máis campos se engadan, máis se incrementan as combinacións e comezará a ser un problema, tanto en complexidade coma no tempo requerido.
Exemplos según tipo de dato
Tipo obxecto
{
"name": "Awesome car",
"reviews": [
{
"magazine": "motor1",
"rating": "5/10"
},
{
"magazine": "world cars 1",
"rating": "6/10"
},
{
magazine: "engine 2",
"rating": "4/5"
}
]
}
Elastic aplanado
{
"name": "Awesome car",
"reviews.magazine": ["motor1", "world cars 1", "engine 2"],
"reviews.rating": ["5/10", "6/10", "4/5"]
}
Con este obxecto podemos facer buscas tipo OR, por exemplo que a revista sexa motor1 ou a puntuación sexa 4/5. Pero non poderemos usar buscas tipo AND, como que a revista sexa motor1 e a puntuación sexa 4/5. Xa que como vemos a relación de que puntuación vai con que revista, pérdese ao aplanar o JSON. Polo que só poderemos buscar neste caso o coche Awesome car se coíncide con que teña nas reviews a revista motor1 ou a puntuación 4/5.
Tipo anidado
{
"name": "Awesome car",
"reviews": [
{
"magazine": "motor1",
"rating": "5/10"
},
{
"magazine": "world cars 1",
"rating": "6/10"
},
{
magazine: "engine 2",
"rating": "4/5"
}
]
}
Neste caso non aplana o obxecto, senón que ten os elementos do array. Isto da máis flexibilidade para facer buscas, pero tamén engade complexidade. Por exemplo poderemos buscar o coche se este ten unha revista ou unha puntuación, pero tamén se ten unha revista e unha puntuación.
Keyword como anidado
{
"name": "Awesome car",
"reviews": [
{
"magazine": "motor1",
"rating": "5/10"
},
{
"magazine": "world cars 1",
"rating": "6/10"
},
{
magazine: "engine 2",
"rating": "4/5"
}
]
}
Ao normalizar os valores para poder buscar, engadirá un campo normalizado dentro do obxecto, neste caso veríase así:
{
"name": "Awesome car",
"reviews": [
{
"magazine": "motor1",
"rating": "5/10"
},
{
"magazine": "world cars 1",
"rating": "6/10"
},
{
magazine: "engine 2",
"rating": "4/5"
}
],
"reviews_normalized": [
"motor1_5/10",
"world_cars_1_6/10",
"engine_2_4/5"
]
}
Como podemos ver ao ter que ir facendo as distintas combinacións, cada novo campo incrementaría moito as opcións. De aí a complexidade deste tipo.
Tipos de mapeos
Car::BRAND_NAME => [ | Prepara un texto
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::TEXT, | analizado para buscar.
ElasticQueryBuilder::ANALYZER => 'analyzer_index', | Non permite ordear,
ElasticQueryBuilder::SEARCH_ANALYZER => 'analyzer_search' | agregar, etc.
],
Car::BRAND_NAME_SORT => [ | Prepara un texto sen
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::KEYWORD,| analizar para ordear
] | ou agregar.
"terms": {
"main_category_name": ["head & body"]
}
"sort": {
"main_category_name_sort": {
"order": "DESC"
}
}
Car::BRAND_NAME => [ | Prepara un texto
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::TEXT, | analizado para buscar.
ElasticQueryBuilder::ANALYZER => 'analyzer_index', | Non permite ordear,
ElasticQueryBuilder::SEARCH_ANALYZER => 'analyzer_search',| agregar, etc.
ElascQueryBuilder::FIELD_DATA => true, | Almacea o campo en memoria para
] | para funcionar como keyword.
"terms": {
"main_category_name": ["head & body"]
}
"sort": {
"main_category_name": {
"order": "DESC"
}
}
Car::BRAND_NAME => [ | Prepara un texto
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::TEXT, | analizado para buscar.
ElasticQueryBuilder::ANALYZER => 'analyzer_index', | Non permite ordear,
ElasticQueryBuilder::SEARCH_ANALYZER => 'analyzer_search',| agregar, etc.
ElascQueryBuilder::FIELDS => [
'raw' => [ | Prepara un texto
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::KEYWORD,| non analizado para
] | ordear ou agrupar.
]
]
"terms": {
"main_category_name": ["head & body"]
}
"sort": {
"main_category_name.raw": {
"order": "DESC"
}
}
Define un campo para buscar, pero que non pode ser usado para ordear ou agrupar.
Car::BRAND_NAME => [
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::BOOLEAN,
ElasticQueryBuilder::DOC_VALUES => false,
ElasticQueryBuilder::INDEX => true,
]
Define un campo para agregar ou ordear, pero polo que non se poderá buscar.
Car::BRAND_NAME => [
ElasticQueryBuilder::TYPE => ElasticQueryBuilder::BOOLEAN,
ElasticQueryBuilder::DOC_VALUES => true,
ElasticQueryBuilder::INDEX => false,
]
Tipos de buscas
"term": {
"has_image": false
}
- Non analizado.
- Só keywords.
- Coíncidencias totais ou nada.
- Bo para boleanos, números, etc.
- Puntuación por defecto de 1.0.
"terms": {
"has_image": [false]
}
- Non analizado.
- Só keywords
- Coíncidencias totais ou nada.
- Bo para boleanos, números, etc.
- Multiples valores.
- Puntuación por defecto de 1.0.
"filter": {
"is_sampling": [false]
}
- Non analizado.
- Keywords.
- Coíncidencias exactas, como term ou terms, pero sen potenciar.
"prefix": {
"has_image": {
"value": "color"
}
}
- Non analizado.
- Só keywords.
- Coíncide con calquera que comece con color.
"wildcard": {
"username": {
"value": "dan?"
}
},
"wildcard": {
"username": {
"value": "fra?"
}
}
- Non analizado.
- Só keywords.
- Coincide con:
- dani
- dano
- fran
- Non coincide con:
- daniel
- dan
- Francis
{
"multi_match": {
"fields": [
"product_name_exact^3",
"brand_name_exact^2",
"category_name_exact^2"
],
"query": "produ",
"type": "best_fields",
"operator": "and",
"boost": 20
}
}
- Analizado.
- Texto e keywords.
- Campos extra para afinar.
{
"bool": {
"must": [
{
"terms": {
"product_id": ["e98b9cbe-ce56-4f80-9773-4d2f9e2b5671"]
}
}
]
},
{
"must_not": [
{
"terms": {
"normalized_extras": []
}
}
]
}
}
| Tipo | Require coincidir | Afecta a relevancia do resultado | Pode ser cacheado entre consultas |
|---|---|---|---|
| must | si | si | non |
| must_not | non | non | si |
| filter | si | non | si |
| should | depende | si | non |
[
"fields" => [
"car_name^3",
"brand_name^2",
"model_name^2",
],
"type" => "best_fields",
"operator" => "or",
"fuzziness" => "AUTO",
"boost" => 1
]
Fuzziness automática
| Lonxitude | Máxima distancia de edición |
|---|---|
| 1-2 carácteres | 0 |
| 3-5 carácteres | 1 |
| +5 carácteres | 2 |
Conclusión
ElasticSearch é unha aplicación que nos permite ter un acceso moi rápido á información que teñamos indexada. Isto en proxectos moi grandes e con moitos usuarios, como tendas online, permite devolver por exemplo á información dos productos en tempos moi reducidos, e sen atacar á nosa báse de datos principal. Así pois os usuario obterían esas representacións dos productos e por outra banda alguén podería estar a editar estes productos, sen problemas por sobrecarga da base de datos. Tan só a cambio de ter que proxectar os datos despois desa actualización, ou aceptar unha incosistencia ata que se proxecte.
Noutro artigo posterior explicarei as buscas e como podemos configurar os nosos obxectos.
Bibliografía
Artigo na wikipedia: https://es.wikipedia.org/wiki/Elasticsearch
Documentación de ElasticSearch: https://www.elastic.co/guide/en/elasticsearch/reference/current