Executando modelos de IA en local con Jan.ai
Executando modelos de IA en local con Jan.ai
Introducción
Neste artigo vou explicar como executar modelos de IA en local utilizando Jan.ai. Esta ferramenta permite non só executar os modelos, senón mesmo descargalos directamente. Permite tamén conectar contra HuggingFace para obter máis modelos, ou mesmo conectar contra modelos remotos. Aínda que isto non o aconsella, xa que o propósito do proxecto é executar en local, para protexer a nosa privacidade.
Instalación
Para instalar Jan.ai temos distintas opcións que dependerán do sistema operativo que estemos a utilizar. Isto inclúe Windows, Mac e Gnu/Linux. No caso das derivadas de Debian, teremos un ficheiro .deb. Para o resto de distros teremos un AppImage.
Actualmente estou a utilizar Fedora e OpenSuse Tumbleweed nos meus equipos. Así que vou polo AppImage. No caso de Fedora non houbo problema, foi descargar e executar. Pero no caso de Tumbleweed si que me atopei con algún atranco.
OpenSuse Tumbleweed erro de certificados TLS
Cando accedía á aplicación dende Tumbleweed todo parecía normal, pero ao acceder a lapela de Hub non tiña modelos dispoñibles.
Procedín a executar a aplicación dende a terminal. Simplemente con ./Jan_0.7.1_amd64.AppImage dende o directorio onde está
o ficheiro. Xa na saída podía ver erros co certificado, erros que se repetían varias veces ao acceder á sección de Hub, onde
deberían aparecer os modelos para descarga.
O erro era o seguinte GLib‑Net‑WARNING … Failed to load TLS database: System trust contains zero trusted certificates
Despois de buscar e consultar con Lumo, recomendaba o seguinte.
- Descartar erros cos certificados do equipo.
- Para isto pedía executar
curl -I https://github.come ver que non tivese erros. - En caso de erro pasaríamos a instalar ca-certificates e actualizalos.
sudo zypper refresh sudo zypper install --force ca-certificates sudo update-ca-certificates
- Para isto pedía executar
- Buscar que tivese os certificados na ruta na que os vai buscar Jan.ai. No meu caso non estaban.
- /etc/ssl/certs/ca-certificates.crt
- /etc/ssl/certs/ca-bundle.crt
- /etc/pki/tls/certs/ca-bundle.crt (neste caso non existía nin a ruta)
- Atopar o bundle de certificados:
rpm -ql ca-certificates | grep -E 'pem|crt|bundle'- A saída foi /etc/ssl/ca-bundle.pem
- Crear enlaces simbólicos das rutas anteriores ao ficheiro .pem.
sudo mkdir -p /etc/ssl/certs sudo mkdir -p /etc/pki/tls/certs # Mudar a ruta ao ficheiro pem, no caso de ter unha distinta sudo ln -sf /etc/ssl/ca-bundle.pem /etc/ssl/certs/ca-bundle.crt sudo ln -sf /etc/ssl/ca-bundle.pem /etc/ssl/certs/ca-certificates.crt sudo ln -sf /etc/ssl/ca-bundle.pem /etc/pki/tls/certs/ca-bundle.crt
Con isto xa o tiven resolto.
No devices found
Na sección de hardware, debería detectar a miña tarxeta gráfica, para poder utilizar a GPU. Instalei os drivers de Nvidia e activei o uso de GPU, pero Jan non a detecta. Non era problema dos drivers, xa que se executo os modelos con Ollama si que fai uso da GPU.
Buscando información parece que está feito a posta. No Discord do proxecto fan referencia a que desactivaron a GPU para tarxetas, con menos de 6Gb de VRAM por probemas. A miña tarxeta é unha tarxeta vella, non teño un PC para xogos, nin unha tarxeta enfocada na IA.
We disabled vulkan backend on GPUs with less than 6GB of VRAM because it was causing lot of problems. Sorry for any inconvenience.
Executando a aplicación
Como dixen antes podemos executar a aplicación directamente con dobre clic no ficheiro descargado. Ou dende a terminal, que para mín só ten senso en caso de problemas para ver os erros na saída.
Ao acceder veremos unha vista semellante a da imaxe.

Descargando un modelo a executar
O primeiro será ir á sección de Hub para descargar o noso primeiro modelo. Dende a web recomendan comezar, con Jan-V1. O cal xa é o primeiro que aparece na sección. Teremos varios dipoñibles de openAI, Grok, Meta, DeepSeek, etc.
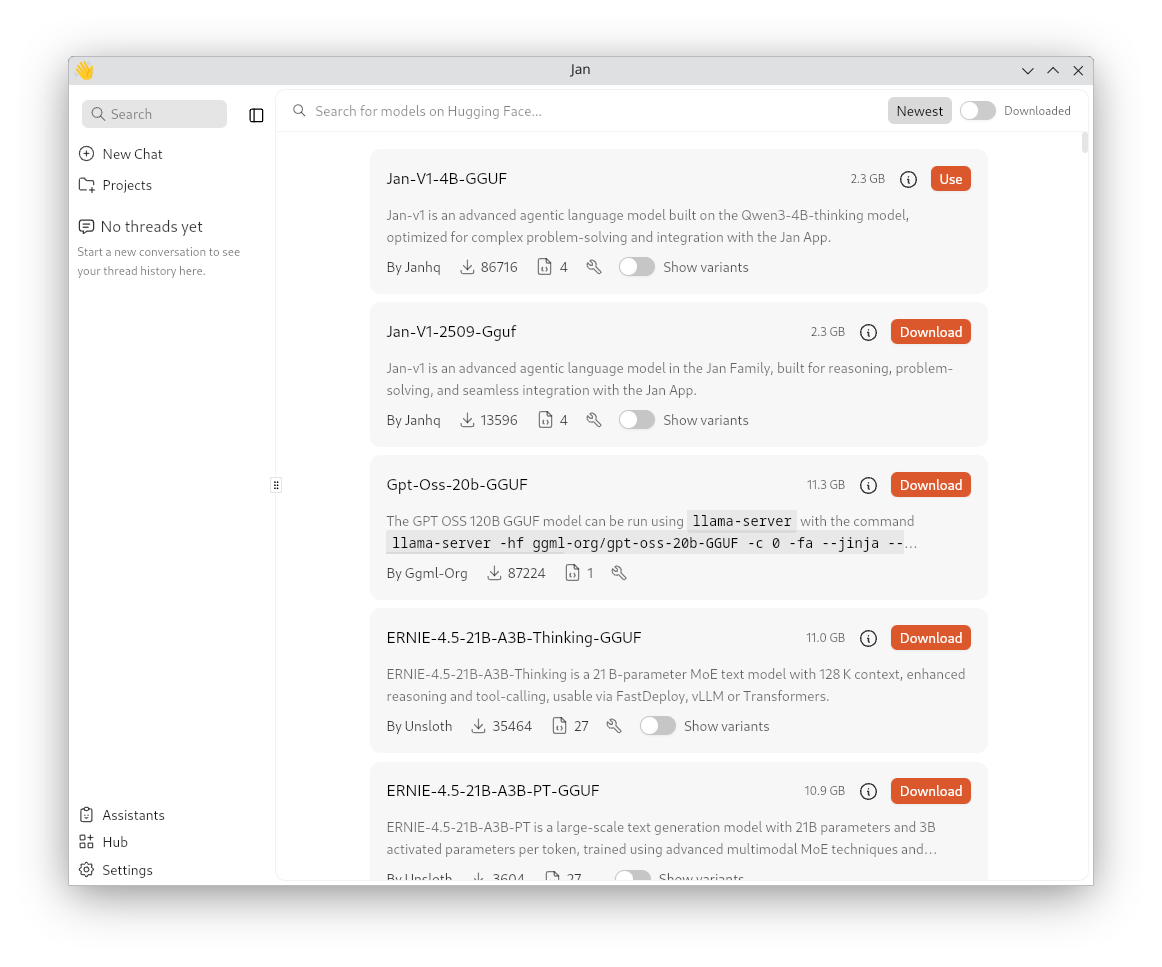
Seleccionaremos o modelo que queiramos e xa poemos probalo.
Falando co modelo
Na lapela de New Chat podemos comezar a falar co modelo. Mesmo escoller na parte inferior que modelo usar. En caso de que teñamos varios descargados, por exemplo para probar cal se nos axusta máis. Ou mesmo para utilizar un en función da tarefa que queiramos. Consultas xeráis ou programar, por exemplo.
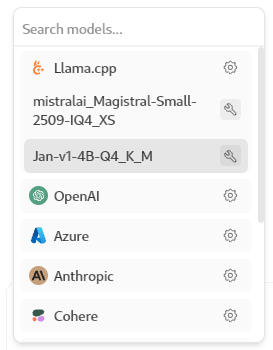
No caso de querer utilizar a ferramenta para conectar contra OpenAI, Azure, etc, deberemos usar o noso token.
Isto pode configurarse na sección Settings. Non só temos opción a conectar con provedores externos. Tamén podemos conectar con Ollama.
Hai que facer un pequeno axuste con respecto ao que ven preconfigurado. Temos que engadir /v1 na URL, para que quede como
http://localhost:11434/v1. Sen olvidar de ter levantado o noso Ollama con algún modelo descargado, ollama serve. Falaremos máis de
Ollama noutro artigo.
De momento tan só probei Jan-V1 e MistralAi-Magistral-Small, ningún dos dous ten saída a internet. Polo que só poderemos tirar deles en base ao coñecemento co que foron entrenados. No caso de Jan chega ata 2023. O de Mistral chega ata 2023 tamén.
Cabe dicir que os tempos de resposta son bastante altos. Neste punto todavía non adiquei tempo a optimizar a configuración. Noutro apartado tentarei mellorar isto.
Asistentes
Isto é algo que me resultou interesante. Na sección de Assistants temos a opción de engadir asistentes. Que son a forma de predefinir Prompts. En troques de ter que pedirlle un comportamento cada vez que iniciemos un chat, podemos predefinilos.
Como dicía, na sección Assistants podemos premer Add Assistant e definir o noso novo asistente. Por exemplo este é o que ven configurado por defecto.
-
O nome é Jan, e ten escollido un emoji 👋.
-
Ten unha descripción, que é opcional.
Jan is a helpful desktop assistant that can reason through complex tasks and use tools to complete them on the user’s behalf. -
As instruccions, que son o que define como se comportará o asistente.
You are a helpful AI assistant, name Jan. Your primary goal is to assist users with their questions and tasks to the best of your abilities. When responding: - Answer directly from your knowledge when you can - Be concise, clear, and helpful - Admit when you’re unsure rather than making things up If tools are available to you: - Only use tools when they add real value to your response - Use tools when the user explicitly asks (e.g., "search for...", "calculate...", "run this code") - Use tools for information you don’t know or that needs verification - Never use tools just because they’re available When using tools: - Use one tool at a time and wait for results - Use actual values as arguments, not variable names - Learn from each result before deciding next steps - Avoid repeating the same tool call with identical parameters Remember: Most questions can be answered without tools. Think first whether you need them. Current date:Como podemos ver isto permítenos ter diferentes personalidades cando falamos ca IA. Por exemplo, podemos definir un asistente que se comporte coma un mestre que non só resolva as dúbidas, se non que nos dé a explicación de por qué. Ou podemos ter un asistente configurado para todo o contrario, que nos dea respostas breves e concisas se non queremos ler unha parrafada, cando só nos interesa unha resposta directa. Por suposto tamén nos permite configurar que se comporte coma un experto en determinada materia, por exemplo experto en Python, experto en historia, etc.
Por suposto isto permite configurar os puntos que vimos no artigo de prompts. O rol que debe asumir, o contexto da petición e formato de saída. Mesmo podemos preconfigurar o idioma da conversa.
- O máximo número de usos que queremos que faga das ferramentas, como as buscas por internet, por exemplo.
- Outros parámetros a configurar aquí son:
- Stream: é un booleano. Se o temos a true irá dando a resposta conforme a vai xerando. A false agardará a ter a resposta compreta.
- Temperature: controla a creatividade da resposta, valores máis altos da respostas máis variadas. Como contra será máis propenso a alucinar.
- Frequency Penalty: reduce a frecuencia de repetir Tokens que xa apareceron anteriormente na resposta.
- Presence Penalty: semellante á anterior, tenta evitar repetir Tokens, pero neste caso no contexto.
- Top P: limita a selección de respostas a aqueles Tokens cunha probablidade acumularda do P% máis alto. Por exemplo, se temos P=0.9. Xerará a partir dos tokens que cubran o 90% da probabilidade acumulada, filtrando as respostas menos probables.
- Top K: limita a selección das respotas a aqueles Tokens con maior probabilidade. Neste caso falaríamos dun valor absoluto. Por exemplo K=40 escollería só os 40 tokens máis probables en cada paso. Limitando as respostas dispersas e máis coherentes. Pero un valor moi baixo fará que sempre nos conteste o mesmo.
A opción de definir os Asistentes resulta moi útil, xa que nos permite ter os prompt de sistema xa predefinidos.
Máis información na propia documentación.
Settings
O primeiro a dicir desta sección, é que non ten Galego como idioma, nin tan siquera Español. Pero ao tratarse dun proxecto libre, temos a opción de colaborar para a traducción. Polo demais son as opcións habituais, fonte, cores, carpetas, atallos de teclado, etc.
Nos Model providers podemos configurar os provedores. Isto non elimina opcións de descarga do Hub. Aquí podemos configurar a nosa conta con algún dos providers que aparecen. Por exemplo quen teña conta en OpenAI, poderá por a súa API Key e conectar contra os servidores de OpenAI. En troques de correlo local. A salvedade de isto é Llama.cpp, que é o provedor local. O encargado de correr os modelos que nos descarguemos. Tamén nos permite desactivar aqueles que non vaiamos a utilizar, de xeito que non aparezan entre as opcións a escoller na sección de chat.
No Local API Server poderemos configurar o asistente a traballar como API. O que nos permitirá conectar outras aplicacións ao noso asistente. Poderemos configurar o porto, o prefixo da API. Escribir a nosa propia API Key, para que non se nos conecte calquera e mesmo filtrar que direccións permitimos que accedan.
MCP Servers
Entre as opcións de MCP atoparíamos o que nas conversas aparece como ferramentas. Por exemplo a opción de conectar cun navegador, para saír a internet. Para isto activaríamos, por exemplo, Browsermcp. E nun navegador con base Chromium instalaríamos o complemento Browser MCP, seguindo os pasos para activalo e sen olvidar de darlle a conectar na extensión. Por deixalo aquí anotado, aínda que está nos pasos anteriores, debemos ter Node.js instalado no noso equipo. A configuración de browsermcp que ven en Jan,xa nos vale sen cambios.
Con este MCP se facemos preguntas como pedir un prezo actual, o axente conectará co navegador para facer a busca e darnos a información.
Conectar cun editor ou IDE
Para conectalo cun editor, o primeiro que temos que facer é ir a Settings e activar o Local API Server. Eu non mudei nada da configuración,
e puiden conectar sen problema.
Por exemplo para conectar o editor Zed, iremos á configuración na zona de chat e engadiremos un novo provider.
Darémoslle o nome, a url http://localhost:1337/v1 (se non a mudamos), a API KEY e nome do modelo exacto que queiramos usar. Dependendo do modelo escollido terá acceso a internet ou non.
Por exemplo o jan-nano admite conexioń. Pero deberemos ter configurado o MCP Server coma dixemos antes.
Conclusión
De momento quédanme cousa por probar. Pero dicir que facilita moito o uso de modelos locais e a conexión con outras ferramentas. Xa sexa que queiramos utilizalo coma asistente de código, como frontal para chatear contra un modelo executado con Ollama, ou para conectar con ferramentas en liña coma ChatGPT. Pero non só facilita a conexión, tamén ese prompt inicial que doutro xeito tendemos a copiar e pegar cada vez. Aquí tan só temos que escoller o asistente e el se encarga de todo.
Por exemplo un que se comporte coma titor, coma documentalisa, axente de viaxes, etc.
Recomendable tamén acceder ás canles do proxecto para buscar máis información, informar de erros ou ver que se coce.
Fontes
- Documentación de Jan: documentación
- Github do proxecto: Github
- Discord: Jan